60% 女性怀疑过自己的性取向 | 可能是国内首个同性恋基因研究
各色人类研究中心 2019-3-7

大家好,我是各色人类研究中心做基因-特征关联分析的雷雷。
我今天是来交作业的。
上个月,各色 CEO 郭婷婷发了条推文,立了个 flag :我们在一个月内启动关于同性恋基因的数据分析。

为表决心,CEO 同学一写完那篇文章,就哐叽一下搬到了我对面……
 于是,在她每天的「殷切注视」下,我和团队,带着连续工作了 N 小时的服务器们提前交卷了。
于是,在她每天的「殷切注视」下,我和团队,带着连续工作了 N 小时的服务器们提前交卷了。
但,我一点都不想现在就直接宣布同性恋研究的结果(暗戳戳的报复)。
接下来我邀请你,和我一起场景再现 「如何从一堆数据里找到同性恋基因」——相信我,了解这个过程比直接告诉你答案有意思多了。
 同性恋基因研究难点在哪里?
同性恋基因研究难点在哪里?
作为一个科学官,我并没有大家想的那样每日沉迷于研究,耳根清净。
这才是我的日常:
*记住这张图
看到我的表情了吗?当时我内心的 OS 是:你们想要问的,其实我很早就问过自己和团队了好吗!
同性恋基因研究到现在差不多 30 年了,为什么所有试图发现单个决定「同/双性恋」基因的研究都无一例外失败了呢,难点在哪里?
我和小组不止一次讨论过这个话题:
所以,总结一下,我想说的是:
(但其实,我也想…)
所以,我抛出的第一个问题是:我们的数据量和数据质量行不行?
 我收到了一份数据宝藏
我收到了一份数据宝藏
1年,5 万数据,国内大规模的性取向关联基因数据库
时间回到一年前的今天,同样是三八节前夕,我们发布了一个关于性别议题的调研:人有 32 种性别,你是哪一种?
这份旨在帮助理解性别平等议题与性少数群体的问卷,在 LGBT 群体中获得了支持和传播。也让我们看到了建立国内大规模 LGBT 群体基因数据库的可能性。
3.8. 2018 我是一个 D 罩杯的直男 | 32 种性别测试发布
3.15.2018 7099 数据
发布初步结论:我们鉴定过了,Gay 比女生都温柔 | 各色独家研究
8.17.2018 33000 数据
发布:中国同性恋分布地图:重庆和成都,哪里才是 GAY 都? | 各色独家研究
…
(了解我们的都知道,这中间我们忙升级去了)
…
时间过得好快,这份研究在后来没有任何推广的前提下,仍然是问卷里的人气王。
于是,经典又重现了:
*经典逼雷图
2.13.2019 49963 数据
各色发文:last call
2.28.2019 问卷数据破 50,000,关联基因数据近 10,000
运营老师星星眼一路小跑兴奋地过来和我通报:
这应该是国内规模较大的性取向关联基因数据库了!
就这样,接力棒历时 1 年交到了我这里。
 解决了数量,再看数据质量
解决了数量,再看数据质量
经过确认,9338 名有芯片基因数据的用户报告了自己的性取向 ,其中男性有 4938 人,女性有 4400 人,比例接近 1:1,还不错。
但是接下来问题来了:
做基因-特征关联分析的第一步,需要明确你要找「什么特征」的基因基础——定义越精准,测量越客观,结果更好解释。
也就是说 ,我们要从 9338 名报告了性取向的基因数据用户中筛选出完全是「同性恋」的人群。
我们先按照大家的自我报告进行了分类,问卷中的第 8 题,不知道你是否还有印象:
这个结果让我非常惊讶,我猜你可能也想不到: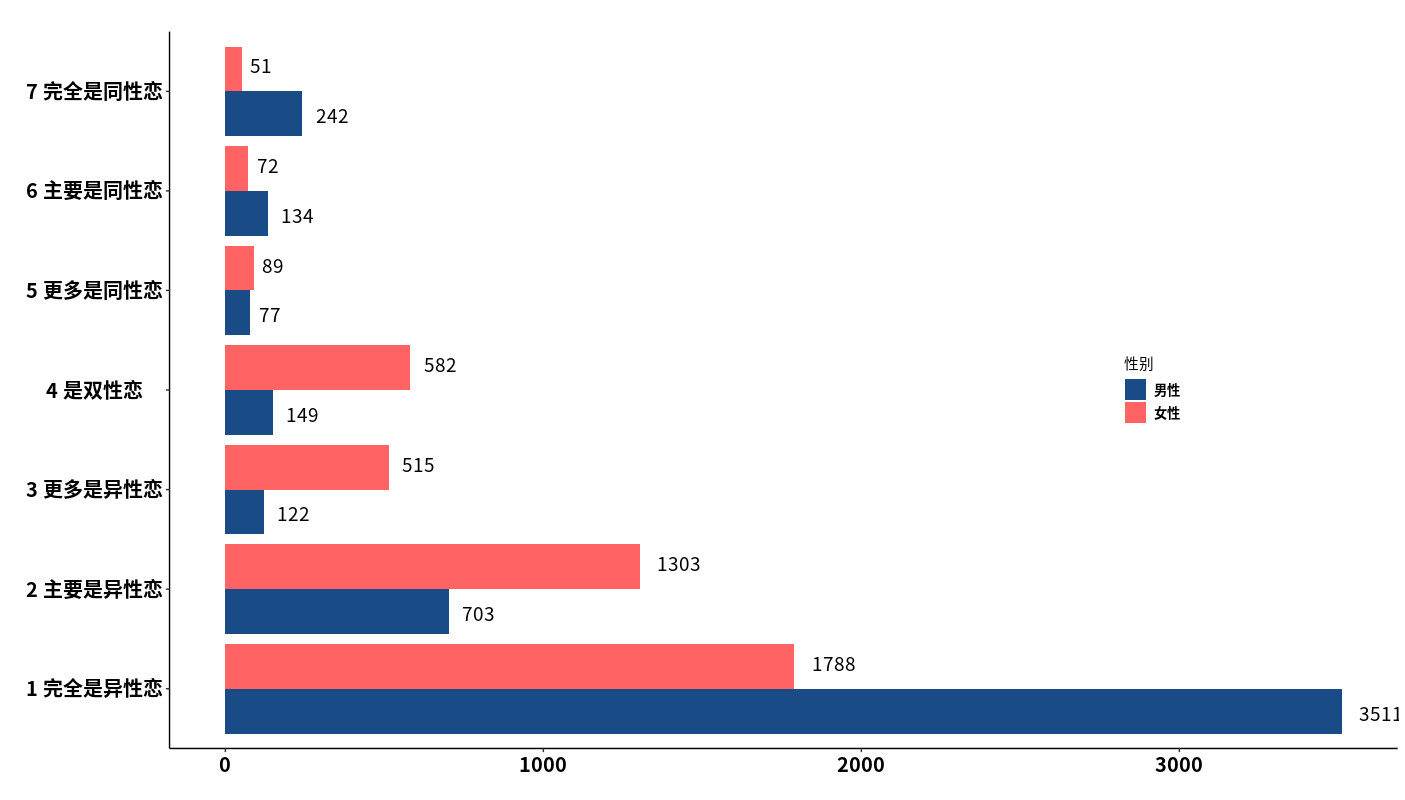
约 70% ,共 3511 名男性认为自己完全是异性恋;筛掉那些不确定的选项,完全是同性恋的只有 242 名,占 4.9%:
相对来说,认为自己完全是异性恋的女性只有 40% ,1788 名:
这听上去我们有机会获得更多同性恋女性的数据,但结果却是:
完全是同性恋的女性只有 1.2% ,更多女性是双性恋。(回顾下我一开始说的:当前学术界针对女性同性恋基因研究几乎没有。不幸我们又遭遇了。)
What’s the point?
划重点:
1 绝大部分直男「宁死也不会去怀疑自己的性取向」:
2 很大一部分直女,却对自己的性取向「保持怀疑态度」:
3 但「真」男性同性恋比例显著高于女性同性恋 :
这当然是数据里的意外收获,但是看着同性恋的人数我们实在是开心不起来。5 万数据,真正能用到的不到 500 份。
不过对于我们数据科学家来说,始终发扬有什么数据做什么结果的优良传统,坚守不对数据挑三拣四和依个人喜好随意改变的底线。不管是 100 个数据,还是 100 万个的数据,我们都一视同仁,该咋做就咋做。
更何况,我们已有的几百个数据,考虑到国内国际方方面面对这块的研究都少,也已经是国内较大的同性恋基因数据库了…
为了高质量研究,继续筛数据
什么,数据已经这么少了,还要筛?
是的,要大数据量是我,要筛数据还是我。
但,我和官老师依旧决定:

以下是原因,如果不是专业领域内人士,看起来可能会有些费劲,但你都看到这里了,就看下去吧。
简单来说,所谓的筛数据主要会经历以下几步:
第一步 分 case 组和 control 组
使用 242 名认为自己完全是同性恋的男性,作为 case 组,标记为 1, 随机在 3511 个钢铁直男中选择 200 个作为 control 组,标记为 0 。
使用 123 名认为自己完全是和主要是同性恋的女性,作为 case 组,标记为 1, 随机在 1788 个钢铁直女中选择 200 个作为 control 组,标记为 0 。
!!!由于研究问题的特殊性,请注意 1 和 0 作为分类数据,不代表任何其他意义~
第二步 选择研究方法
探索基因位点和特征之间关系的方法有很多,我和官老师决定先使用该领域的经典爆款方法—— GWAS(Genome-wide association study),即全基因组关联分析研究,来进行初步探索。
第三步 筛位点数据
按照标准的 GWAS 分析流程,我们要针对基因位点和人进行质量控制。检测位点的控制不用说了,反正每个人可以供分析的有好几百万基因位点,删就删点儿,不影响。
第四步 筛人的数据(这也是我最心痛的)
为什么要筛?
当然是防止得出假的结论。
人的质控主要有 2 方面:
一是删掉有明显亲缘关系的人,一家出一个代表就行了,要都是一家人,算出来的结果就有问题了。
二是要控制祖源,说到这里让我们再次复习各色制作的中国同性恋分布地图: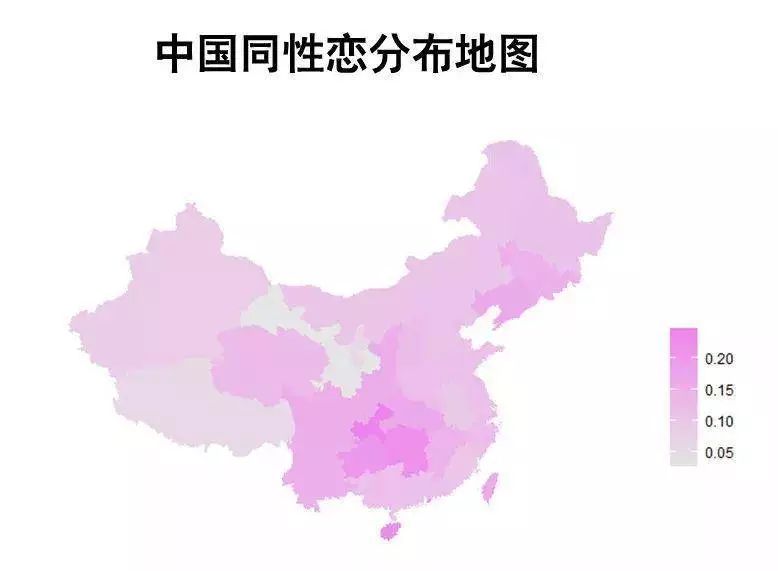
从图中看西南地区同性恋人群比例明显更高。
想象一下,如果我们不控制人的地区,很有可能,一些区分祖源地区的基因位点,会被误认为是区分性取向的基因位点。
得出诸如从基因上「同性恋≈西南地区人」这种石破天惊的结论……
但,CEO 婷姐说——
具体怎么做呢?
我们选择用无监督聚类。
比如针对男性来说,将我们 242 名同性恋和 200 名异性恋使用 PCA 做聚类,找到祖源离群点,比如下图在圆圈内的人就是一个离群点。将离群点筛掉后,再次做聚类,将聚类产生的一些祖源相关参数带到最后的计算中。
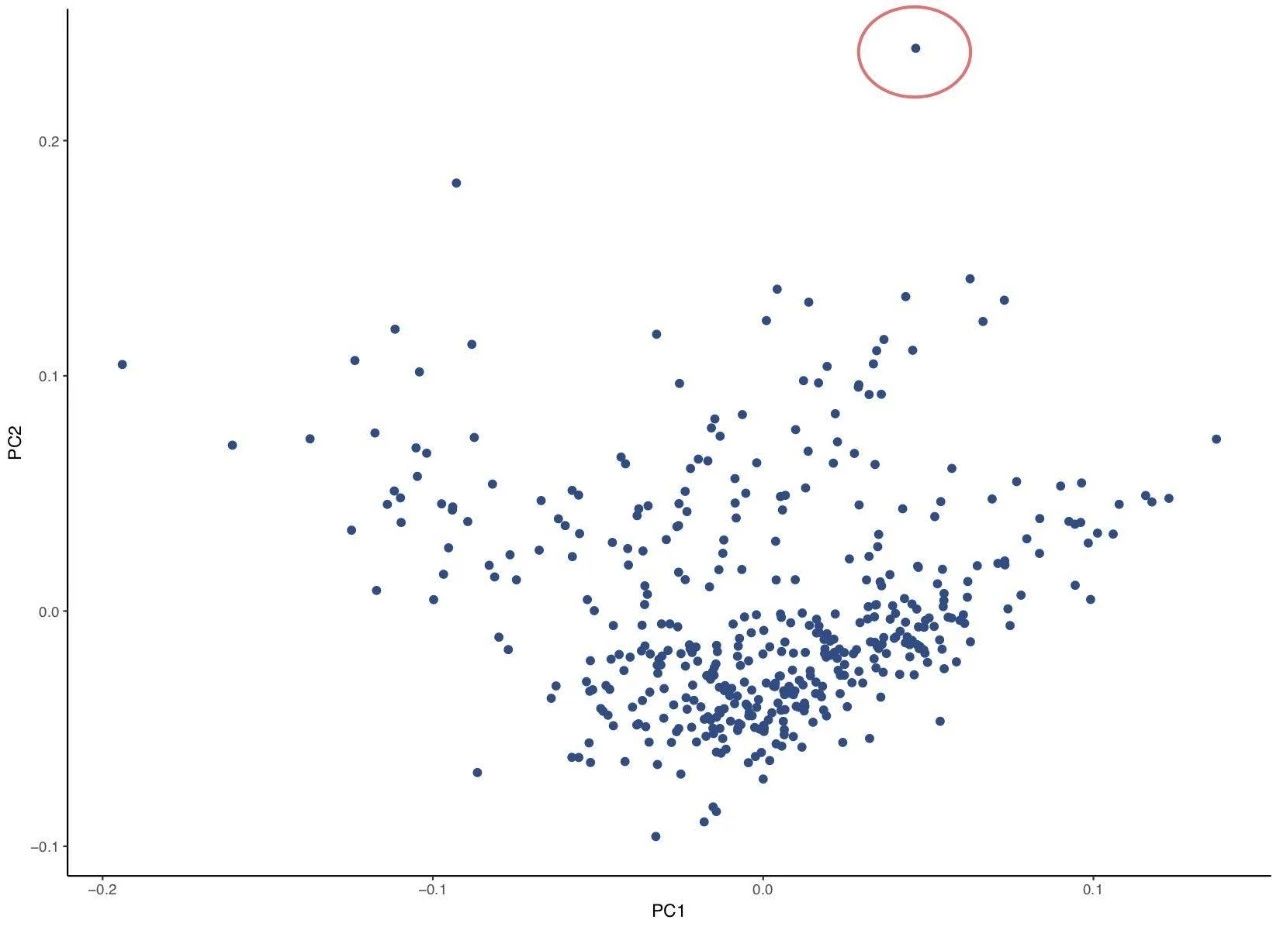
就这样通过一系列的质控,在和我官老师的祈祷中,

最终保留下了:
男性同性恋 219 人, 男性异性恋 182 人;
女性同性恋 110 人,女性异性恋 185 人;
其中每个人可以用来分析的基因位点有近 100 万。

正式开工,结果是…
等等,再往服务器那屋放点儿吉祥物… (没别的意思,就是希望它跑的快一点)

等……
等……
我们在等一张曼哈顿图:

什么是曼哈顿图?
GWAS 分析是相对简单的,我们使用逻辑回归(针对 1 和 0 这种分类的特征),控制了人的地区来源等可能影响性取向的特征,然后对每一个基因位点进行统计检验,看看这个位点是否影响性取向,结果一般就用所谓的曼哈顿图来表示。
曼哈顿高楼林立,有高有低。如果我们把人多条染色体的基因位点,按照 GWAS 分析得到的效应值排列,会特别像上面这个图。
图中最惹人注目的便是新世界贸中心,做 GWAS 分析的人也特别希望在属于自己的曼哈顿图中看到「新世贸中心」,这意味着:我们的研究找到值得解读的基因位点了。
等的结果是:
我们的男性和女性性取向的曼哈顿图长这样—— 横坐标是染色体数,纵坐标是 gwas 分析效应;按照 GWAS 分析的要求, p 值小于 5 x 10 -8 的基因位点才可能有意义。
也就是说,下面 2 个图片的纵坐标需要到 8 。
然而实际呢?看图:
(男性图)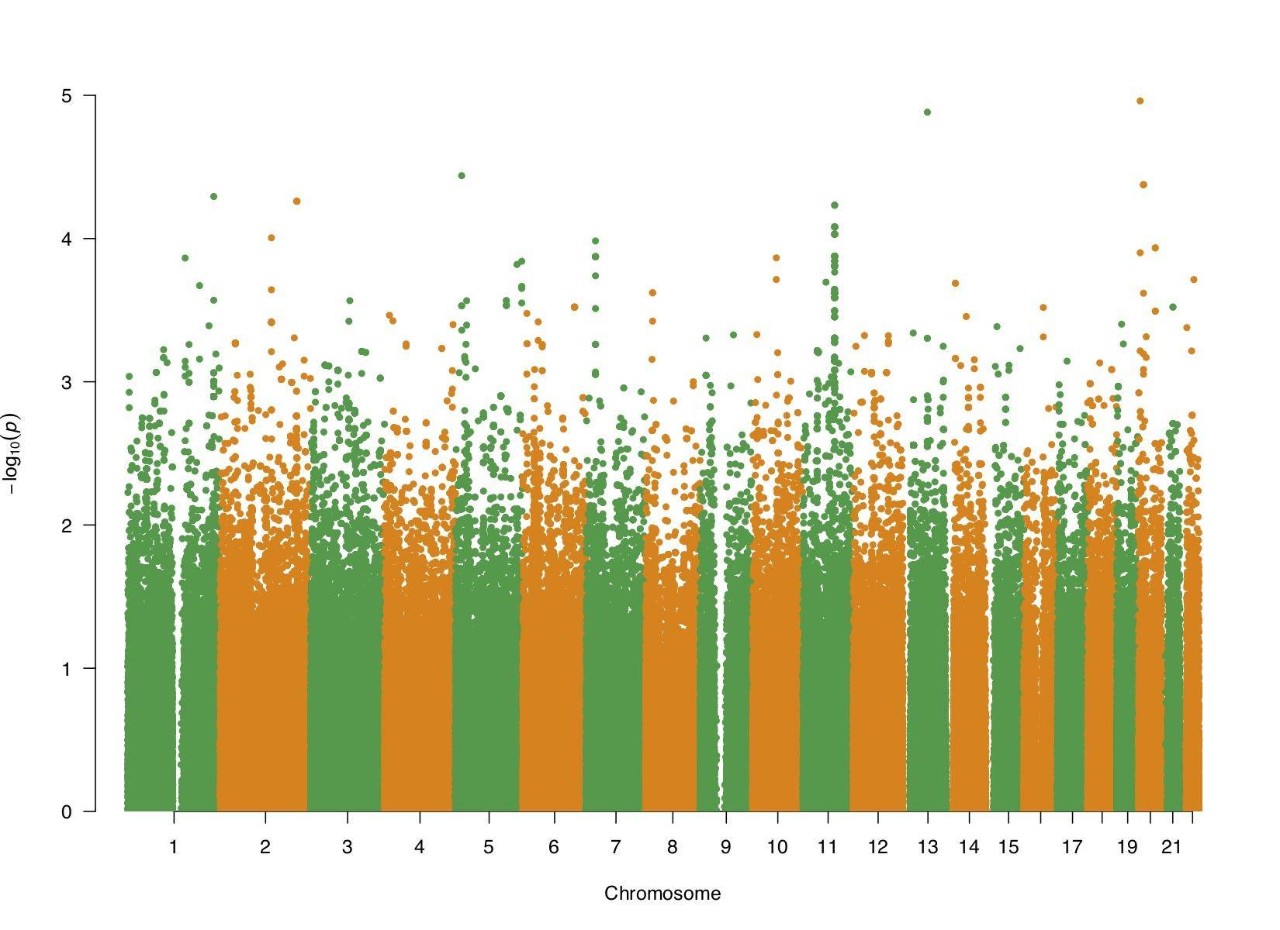
(女性图)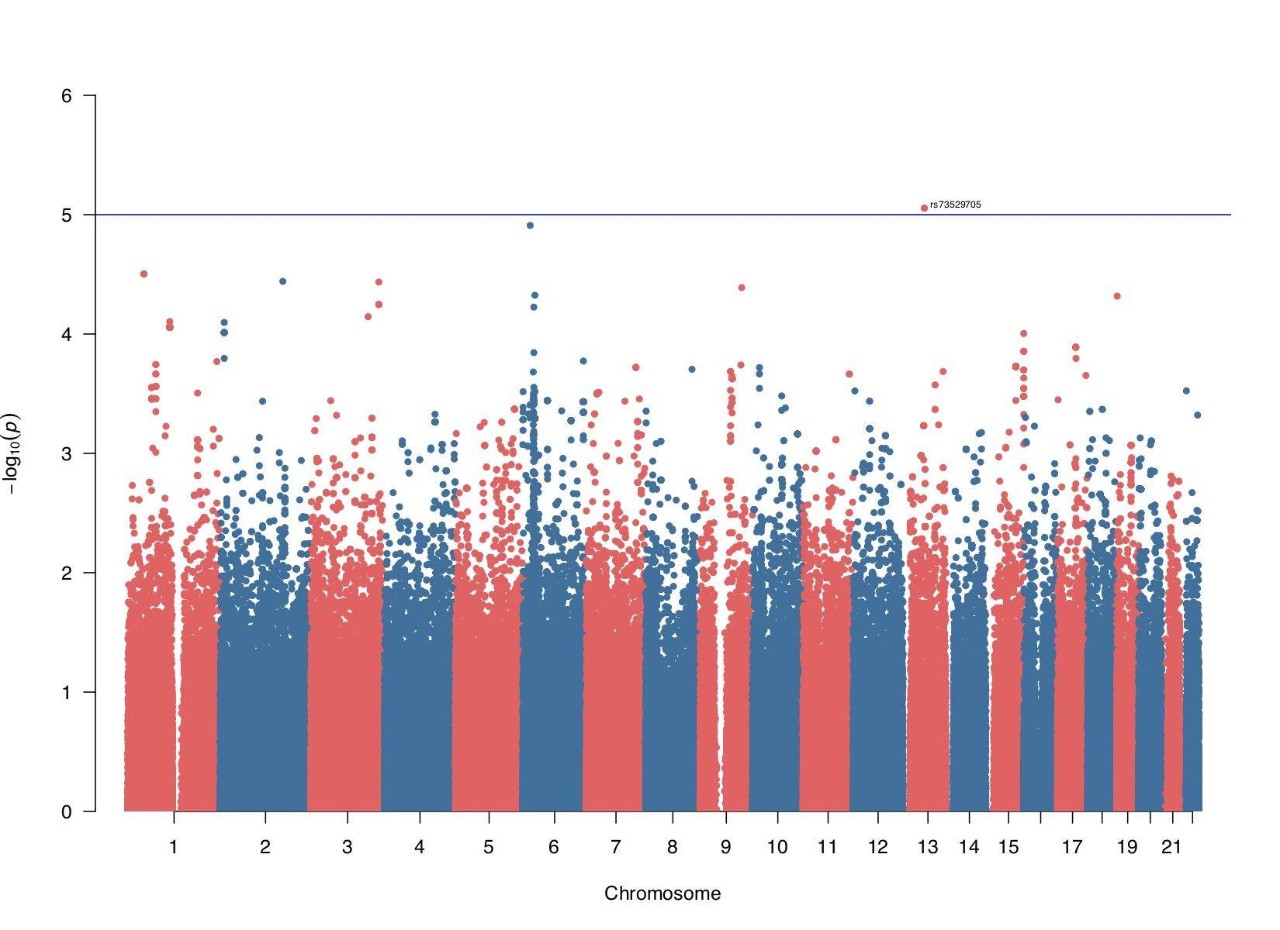
很可惜,我们没有看到属于它们的「新世贸中心」。
使用当前的数据和方法,我们没有找到显著影响性取向的基因位点。
当然我们的同行之前也没找到。
2012 年, 23andMe 研究团队针对 13733 名男性同性恋做了 GWAS 分析,发现 8 号染色体上 rs77013977 基因位点,可能存在效应,但仍未达到 GWAS 结果显著的标准。
2017年,Sanders 等人针对 1077 名男性同性恋做了 GWAS 分析,发现 13 和 14 号染色体上 rs9547443 和 rs1035144 可能存在效应,但仍未达到 GWAS 结果显著的标准。并且他们也没有重复出 23andMe 团队的研究结果。
在长期做一线研究的我和官老师看来,一次实验没有结果,并不意味着失败,而是帮我们更深入的认识了「同性恋」这一特征的行为和遗传规律。
但虽说如此,我和官老师还是有些怅惘。
 同性恋行为有进化意义
同性恋行为有进化意义
将数据结果整理完,我和官老师讨论起了同性恋的进化意义:
同性恋者如果只和同性发生性关系,自己的基因是无法传递的,按照经典的达尔文进化论,这是一种阻碍生殖的行为。
但是为什么这种行为会一直保持下来呢,包括在动物界也很常见。

Roy 和 Silo,世界闻名的企鹅同性情侣。
学界关于同性恋行为的进化意义,主要有 2 种探讨:
第一种认为:同性恋行为可以提高后代的繁衍和生存概率,当然他们照顾的不是自己的后代,而是爸爸妈妈或者兄弟姐妹的后代。不过,目前并未发现同性恋者在照顾孩子的意愿和技能上有过人之处。
第二种则认为:同性恋行为并非有什么生殖优势,它是一种生存策略,为的是与同性结盟,建立「友谊」,提高自己的生存概率。先生存,再生殖,听着似乎更合理。
再说有数据发现,双性恋行为似乎比同性恋行为更加普遍。
 同性恋基因研究的难点可能在于「同性恋的定义」
同性恋基因研究的难点可能在于「同性恋的定义」
说到这里,我突然意识到,我们之前按照大家自我报告对性取向分类只是其中一种,如果按照人们实际发生性关系的对象来分类呢?
恰好,这道题我们也设计了:
 那让我们来看看男性和女性性关系对象:
那让我们来看看男性和女性性关系对象:

从上图看来,发生性关系的情况,男女的模式差别看起来不大。
我感兴趣的是:只和同性发生性关系的人群,他们又是如何自我报告自己的性取向的呢?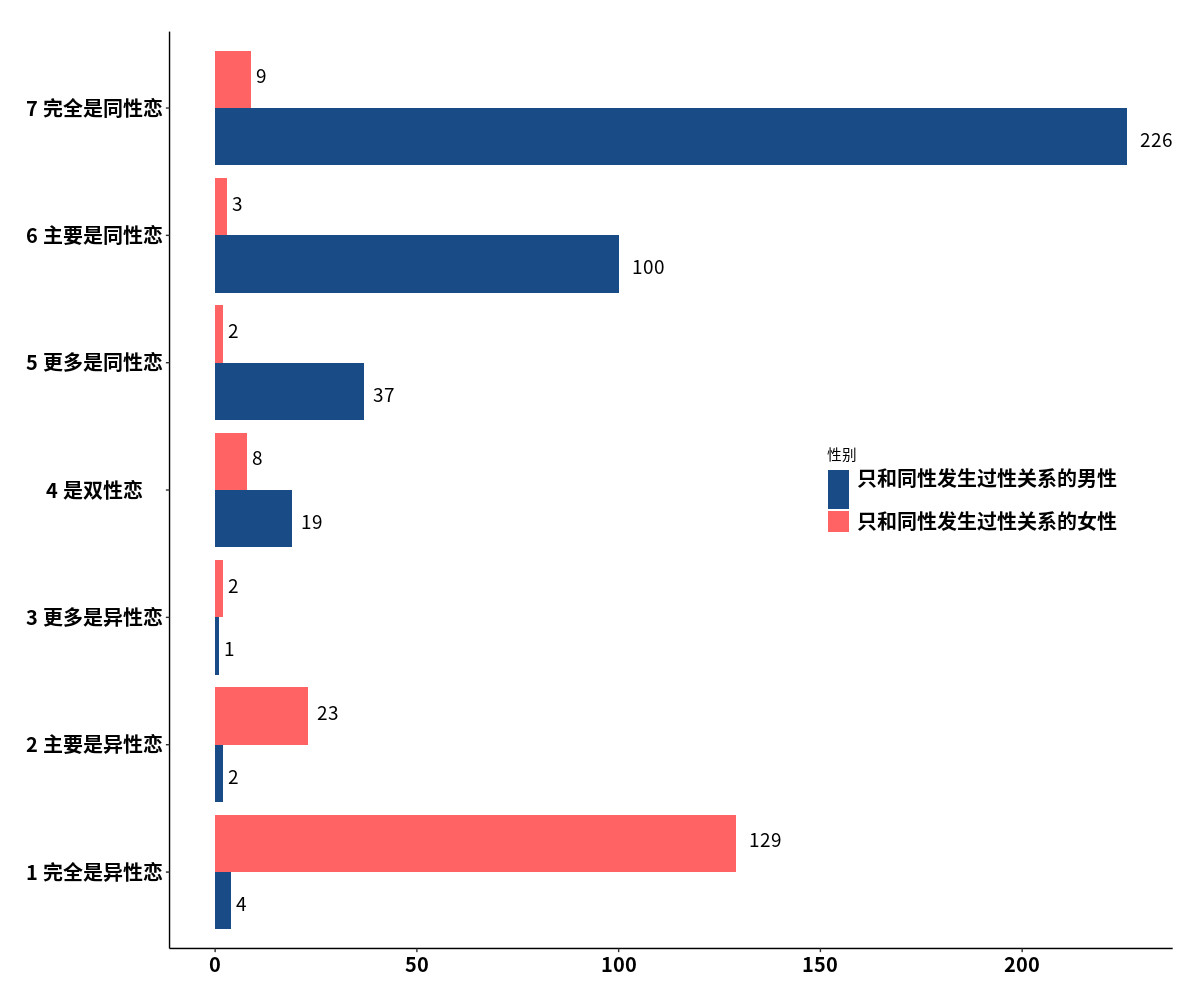
上图中,在 389 名只和同性发生过性关系的男性中,他们自我报告的性取向,结果看起来很 make sense。
但,在 176 名只和同性发生过性关系的女性的「性取向报告」,又让我意外了:
176 名只和同性发生过性关系的女性中,只有 9 名女性认为自己是同性恋,有 129 名认为自己是异性恋。
???
身为女性的我,发现我真的有点不懂女性……
这个发现提醒了我:
我们一开始设定的按「自我认知」来定义同性恋人群来做数据,可能太简单了。
(回顾知识点:第一步需要明确你要找「什么特征」的基因基础,定义越精准,测量越客观,结果更好解释。)
那,同性恋究竟是按照自我认知来划分,还是按照是否和同性发生性关系来划分呢?
这还真有些复杂。
看到这里,我和官老师面面相觑,都看向了正在整 Tensorflow 的我司东北辽宁沈阳籍算法工程师宋老师。结合他的新技术,基因和性取向的研究会有新结果出来吗?
换个思路再来…
是的,我们暂时还没有结果。
看到最后,我想你可能明白了:「同性恋基因研究」听上去噱头十足,但各色要做的不是一个噱头。
严谨的研究,需要大体量的数据,严格质控的高质量数据,周全的实验设计,试验不同的分析方法…
最需要的是:耐心和你的参与。
那究竟多少数据才足以支撑我们发现有意义的基因位点呢?
下面这张图能给我们一些参考。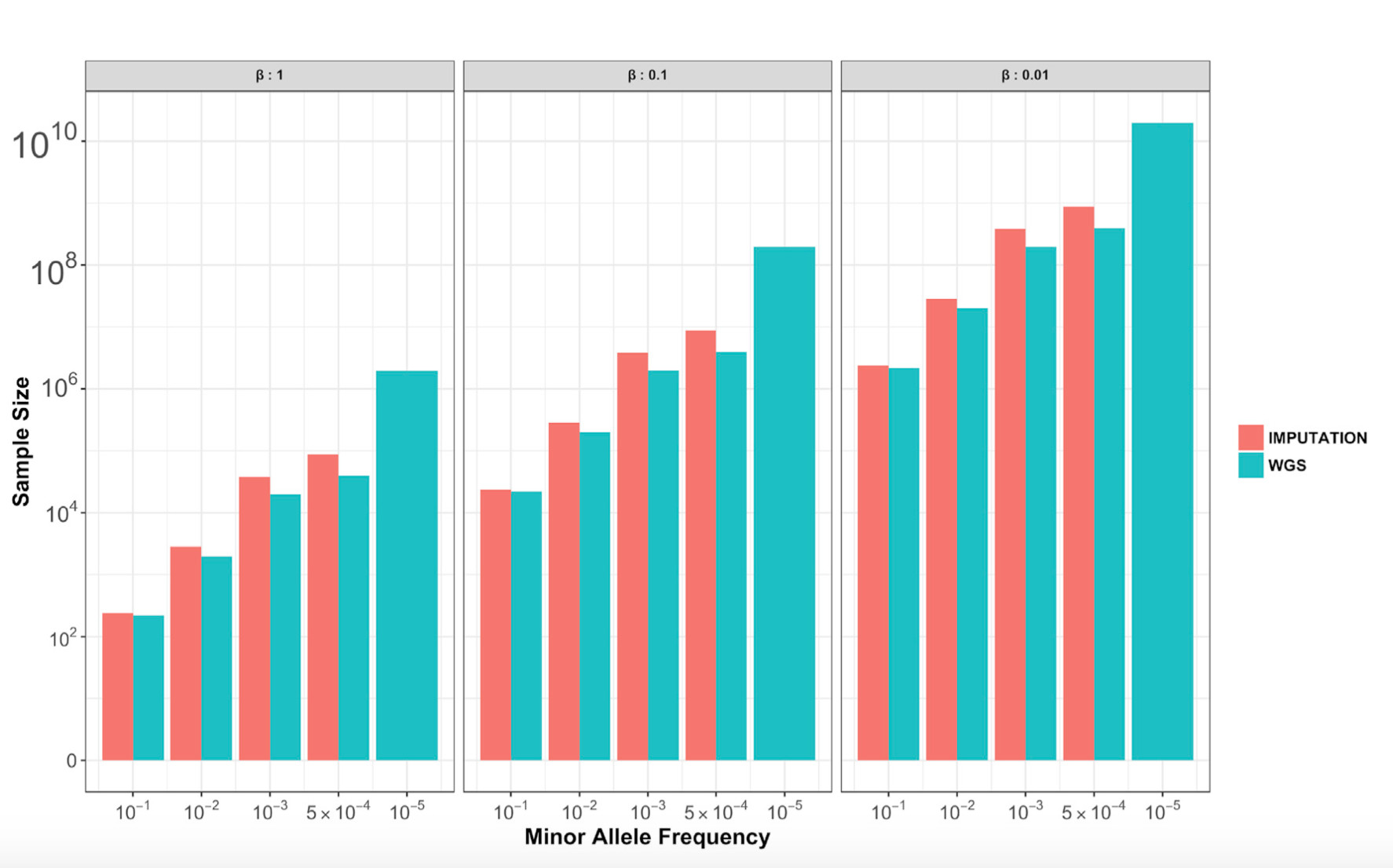
对那些与基因相关性强的特征,只需要几百人就能发现有显著效应常见位点。特征与基因相关性越弱,关注的基因位点在人群中越不常见,需要的人数就越多。
最后还要严肃强调的是:我们专注于群体特征的挖掘和描述,但,群体的规律也许和你个人特征不符。
并且,我们数据分析团队没有权限获得能识别大家身份的任何个人信息,比如电话和地址等。所以,请不要担心任何数据隐私问题。未经你的知情同意,我们也不会和任何其他机构分享你的数据。
我们的数据挖掘还在继续,虽然同性恋解读暂时没结果,但其他特征的基因-表型关联研究已经有了不少进展,例如祖源,身高,性格……都已经有了基于各色自有数据库的最新研究成果。
限于篇幅,这些内容会在接下来的推送中陆续跟大家介绍,一定要关注我们哦。

最后,再介绍下我们是谁

各色DNA(gesedna.com) 是一个通过科学方法帮助年轻人了解自己的研究型商业机构。
在过去一年中,有数万名好奇心人类在各色完成了人生中第一次 DNA 测试,除了一份持续更新的 DNA 检测报告,他们还参与了各种公民科学研究项目,平均为超过三十个研究做出贡献,这让我们有机会积累了国内最大的基因-人类行为关联数据库。
你的参与,会加速基因科学的进展。
参与各色 DNA 测试,你的隐私会得到非常严苛的保护,我知道你人生中关于「认同」而付出的努力,我想跟你一起改变人类对「如何看待自我」的认知。
如果你还没有在各色做过基因检测,你需要做的:
1. 下单各色 DNA 检测包,收到采样装置后,尽快回寄
2. 完成 DNA 测试与性别研究
接下来是一句各色名言:
如果你已经是 各色DNA 的用户,我希望你把这篇文章转发给你身边的 LGBT 朋友。
现在的 DNA 测试价格已经不再昂贵,但依然是一个高认知门槛的「知识奢侈品」。好在数万人规模的星星之火,已经足够为这个领域的科研进展增加一些光辉。