各色研究员为你解答:祖源成分基因检测是怎么回事
各色人类研究中心2018-11-22

大家好,我是「各色DNA」的基因产品总监雷雷。我的另一个身份是——各色小助手 pro。你们各种科学细节提问,都由我来回答。
读完本文,你将得到我对以下 7 个问题的回应:
1 我的祖源结果是参考哪些信息得出来的?
2 我的外国血统怎么消失了?
3 我怎么知道自己到底是哪里人?
4 我的祖源百分比是什么意思?
5 各色为什么会用区域而不是民族来做祖源成分?
6 我是少数民族,为什么没有检测出来呢?
7 没有炫酷的祖源可以分享,那做祖源还有什么意义?
答疑正式开始:
如果你最近看过自己的基因解读报告,你会发现祖源产品更新了:现在你可以获得全世界 59 个地区和族群的成分解读。
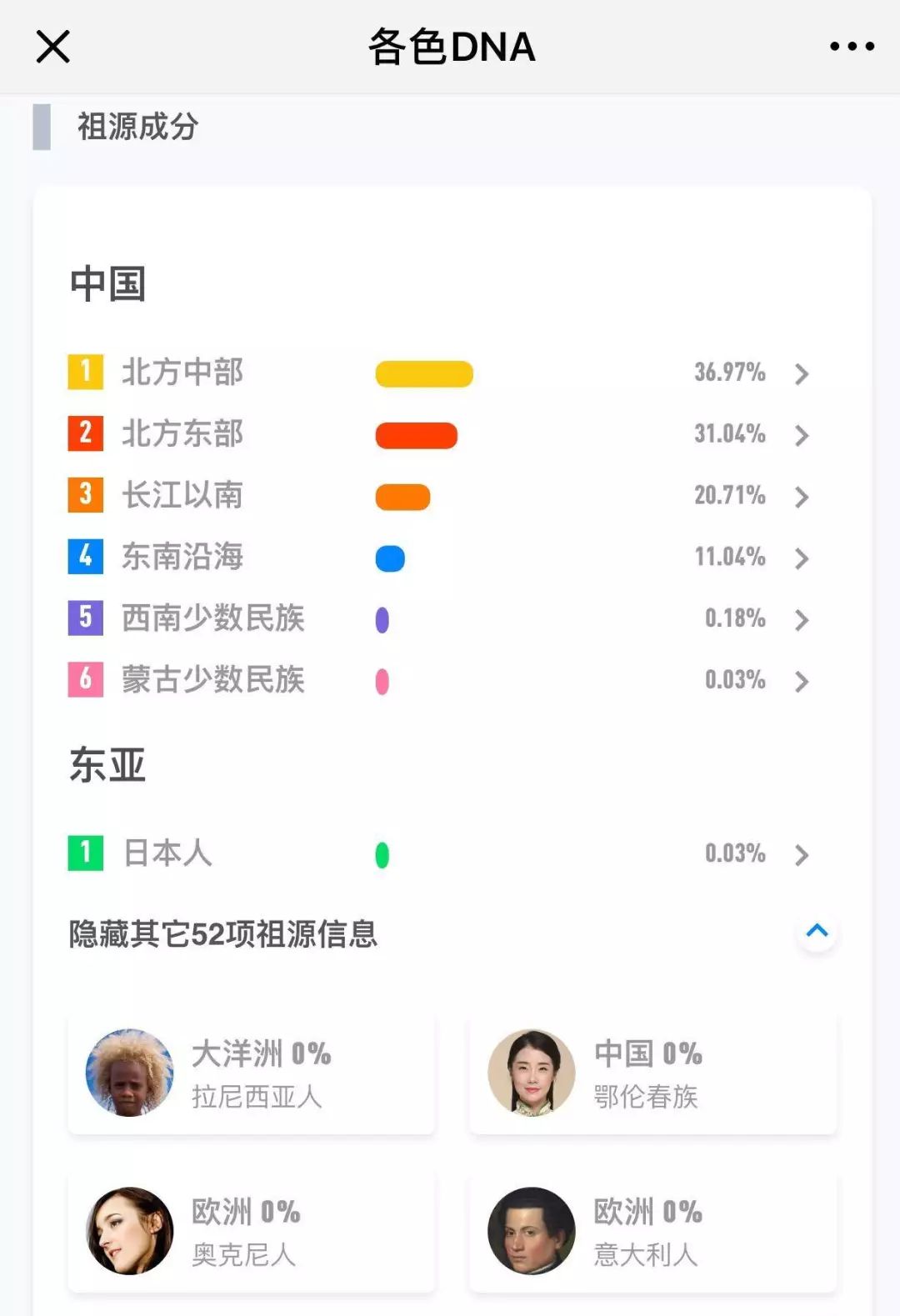
各色小助手第一时间跟我反馈了你们看到新报告的困惑:
我的外国祖源怎么没有了?
这些新的成分是怎么算出来的?
比例的变化应该怎么理解?

于是,pro 版小助手今天上线了~ 我会在这篇文章中,一一解答好奇宝宝们的困惑。
 问题一:我的祖源结果是参考哪些信息得出来的?
问题一:我的祖源结果是参考哪些信息得出来的?
祖源参考数据并不是你的祖先,而是连续几代生活在这个地方的现代人。
拿北方汉族来说,当我们找到足够多长期生活在北方汉族地区的人,我们就构建了一个北方汉族地区的参考数据库。
2016 年,当我刚开始做中国人祖源解读的时候,我发现,几乎没有中国不同地域的基因参考数据库。
即使在全球用户量最大的 23andMe(目前可以探测全球 150 个国家和地区的祖源),中国人也只是被粗略划分为南方人和北方人。
 一个典型的中国人在 23andme的祖源成分检测结果
一个典型的中国人在 23andme的祖源成分检测结果
在我们去年 9 月份发布第一版祖源解读的时候,我们对中国人祖源的探索才刚刚开始。
我们积累的第一版中国人族群数据库,将生活在中国的人分成了 6 个地区,将国外人口分成了 8 个地区。据此给出了每个人的比例解读,并且邀请大家继续参与家庭出生地的调查。
人类对庞大基因组数据的探索一直在继续。测序技术的发展、数据的积累和算法的革新,都会刷新人们对自身的认识。
今年,我们有了更大更丰富的族群数据库。我深知,解读结果变化可能会挑战已有用户的认知,但我们必须做出调整:因为,我们是在共同「养成」一个更好的产品。
23andme 也在不断更新自己的数据库,带来更多祖源成分的解读
各色的祖源由原来 14 个地区,升级为 59 类,主要是源自于祖源参考数据集的优化。
在过去一年里,我们积累的参考数据库包括:
- 最最重要的,由亲爱的各色用户贡献的 DNA 数据
- 国际千人基因组计划中的公开数据(http://www.internationalgenome.org/category/population/)
- 斯坦福大学人类基因组多样性研究计划中的公开数据(http://www.hagsc.org/hgdp/)
你会发现,各个国家和地区的基因数据库并不是一个神秘的黑盒子,而是全人类科研事业的共同财富。
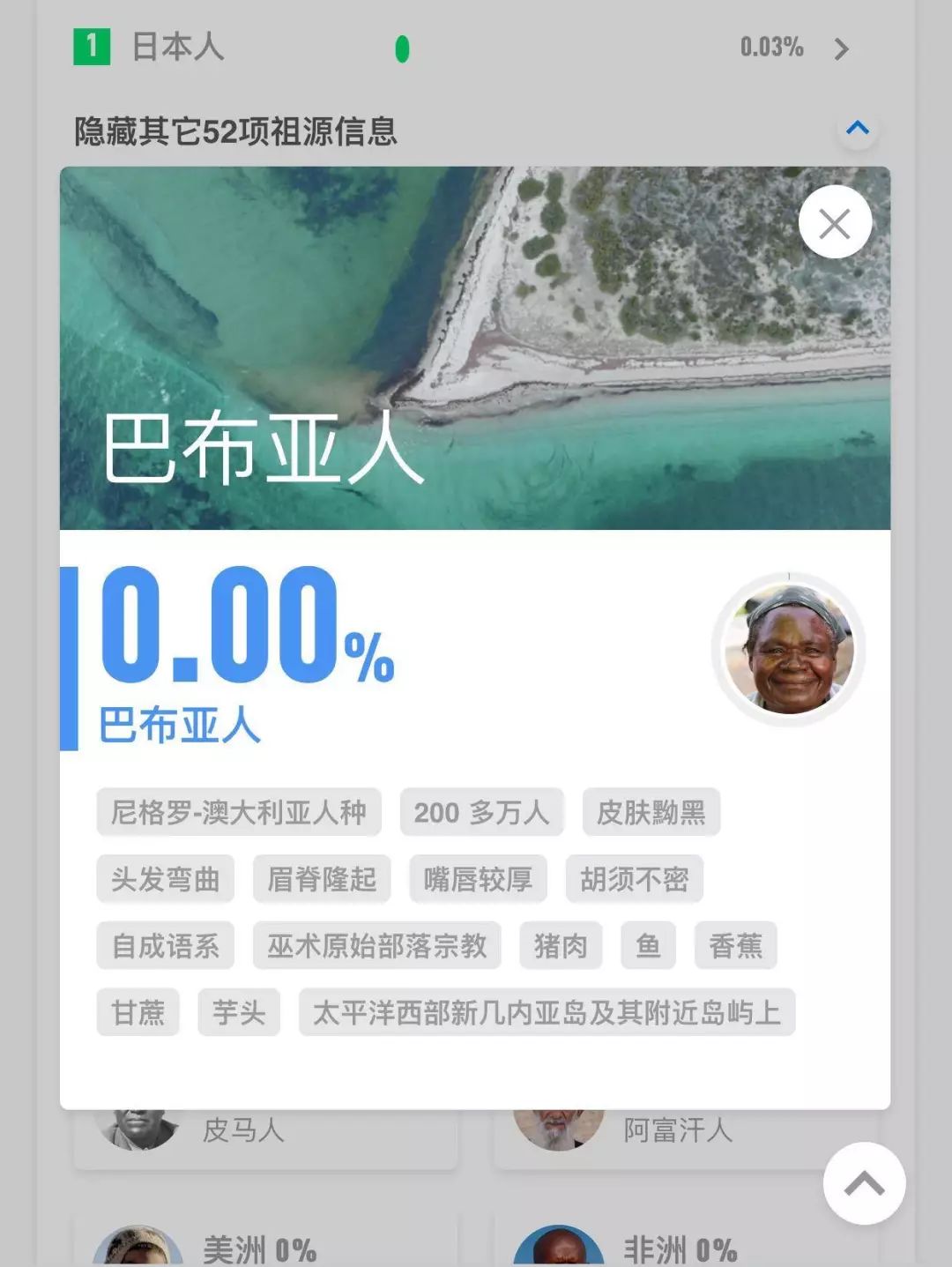
由于各色用户绝大部分是中国人,因此在收集和整理国外不同族群的参考数据时,我们仍然重点分析中国人的数据,特别是汉族群体。
感谢所有这些数据的贡献者,正是你们的好奇心和行动力,让全球更多人可以享受到在基因中探索祖源奥秘的乐趣。是你们贡献的数据,让解读结果变得更好了。
 问题二:我的外国血统怎么消失了?
问题二:我的外国血统怎么消失了?
我看到很多人会乐于在社交网络上分享自己的「5% 美洲土著基因」,这听上去很酷,我的科学解释希望不会让你失望:祖源成分并不代表你一定有这里的祖先,而是你的祖先有 5% 的可能是这里人。
人有 23 对染色体,22 对常染色体,1 对性染色体(女性是 XX,男性是 XY )。做祖源成分分析使用的是 22 对常染色体数据。
人类基因组中,大约 99.9% 的 DNA 序列都相同。所以要通过祖源成分分析获得你属于某个地区或族群的「可能性」,第一步是找到在不同地区和族群分布有差异的基因位点。
比如,影响人是否有腋臭的基因位点是 rs17822931,这个点基因型为 C 的人,体味更重一些。
rs17822931 在世界不同地区的分布差异很大,在非洲有 99% 的人携带 C ,在美洲和欧洲携带 C 的比例是 86%。
而在东亚携带 C 的比例只有 22%,大部分人东亚人在这个位点是 T型,表现为干燥的耳垢和更轻的体味。
如果一个人 rs17822931 检测结果为 TT,从概率上来讲,他更可能是一个东亚人。
 rs17822931 在世界各地的分布,圆圈白色部分指的是 T
rs17822931 在世界各地的分布,圆圈白色部分指的是 T
所以,当我们找到足够多像 rs17822931 这样的基因位点,即在不同地区,不同人群中基因位点类型频率分布有差异的位点, 我们就可以去推测你的祖源成分。
| 族群1 | 族群2 | 族群3 | 族群4 | |
| 位点1(C) | p11 | p12 | p13 | p14 |
| 位点2(A) | p21 | p22 | p23 | p24 |
| 位点3(G) | p31 | p32 | p33 | p34 |
祖源参考数据集示例
计算祖源成分的算法上,我们使用的是美国加利福尼亚大学洛杉矶分校相关人员研发的,也是目前使用比较广泛的专门计算祖源成分的方法—— ADMIXTURE(http://software.genetics.ucla.edu/admixture/)。
其核心算法是极大似然估计法(Maximum Likelihood Estimate,MLE),简单说就是你的基因数据作为「已知现实」,计算出你最可能由哪几种参考数据集中的族群组成,以及相对应的百分比。
所以,当改变了参考数据库祖源地区的划分类别,例如增加或者减少了族群的种类,你的结果就会发生变化。
 问题三:我怎么知道自己到底是哪里人?
问题三:我怎么知道自己到底是哪里人?
祖源结果比例发生变化,并不意味着之前的结果是错误的。全球人类祖先都自非洲,使用不同的参考数据,你能得到自己来源于不同族群的可能性。
例如,跟美洲土著相比,你很可能与日本人的基因相似性会更高一些。
将各色祖源参考数据集所有族群放在一个平面上观察时发现,中国人群内部差异比较小,而非洲各个族群与其他所有族群差异最大,距离最远(下图左上角为非洲族群)。
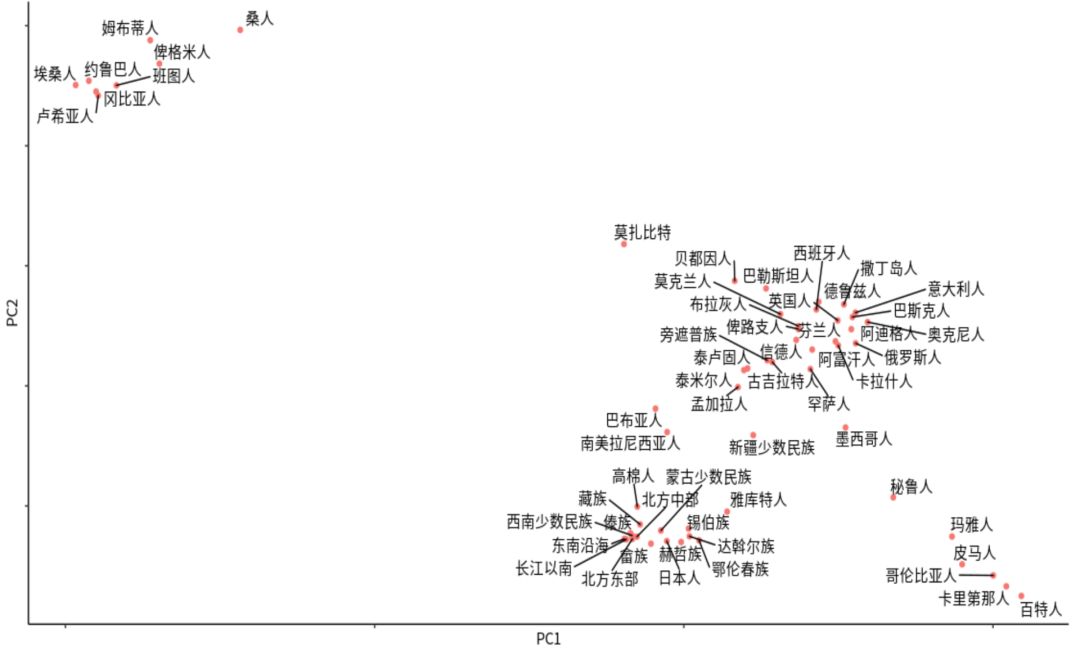
从我们数据库中发现不同地区人类基因相似性的「远近」,可见中国人跟日本人基因模式比较接近,与美洲土著(例如墨西哥人)和澳洲土著(例如巴布亚人)的基因模式也比较接近,而与欧洲人更远,与非洲人最远。
并且生活的地区越相近,基因型分布的差异也越小。对每个基因位点来说,在一个地区为 100%,另一个地区为 0% 的情况比较少。而更可能是 30%,40%,60%,80% 这样的差异分布。
再多说一句,这就是为什么基因武器没有可行性——
因为世界各地基因位点多为相对差异,不可能达到只对某一族群有害,而对其他族群无害的效果。
问题四:我的祖源百分比是什么意思?
把你 DNA 数据中的大量基因位点,和祖源参考数据进行比对,就得到了你的综合预测结果。即你属于这个族群的概率。
比如,我出生在山东,我有 34.44% 的北方东部成分,即我属于北方东部人的可能性是 34.44%。
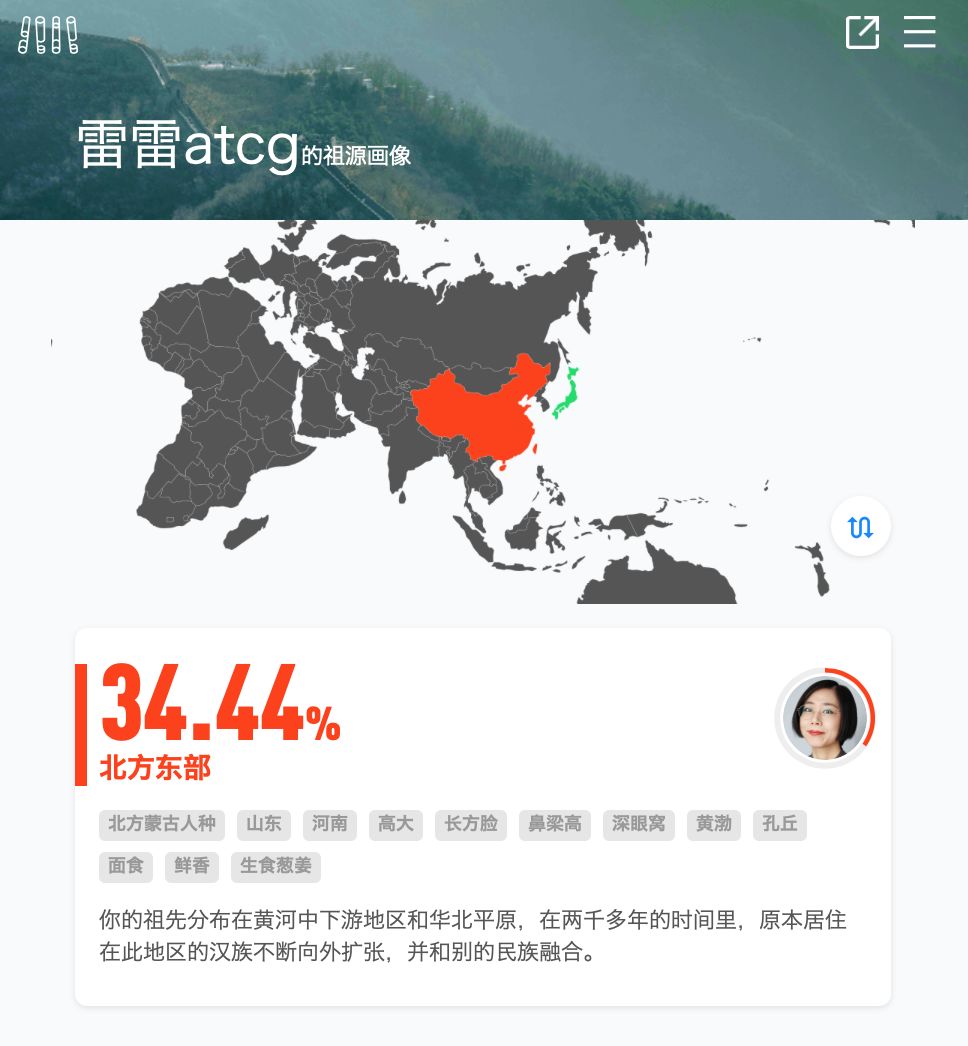
问题五:各色为什么会用区域而不是民族来做祖源成分?
当你看到你的祖源时,我猜你的第一反应可能是:没有惊喜。
大部分中国人是北方汉族或南方汉族主体,如果用民族来做祖源划分,一个汉族人的祖源结果会比较「无聊」。
但其实除了民族之外,基因中还蕴藏着非常丰富的地域差异信息,这些信息正随着数据库积累变得越来越清晰——
今年新发表的一项大规模中国人祖源研究,根据 19 个省和直辖市共 11670 名汉族人的分析发现:汉族人南方和北方之间的差异是最大的。
北方省市中,甘肃、陕西和山西,与其他省市(东北三省、山东和河南等)有差异。
相比北方汉族呈现出来的东西差异,南方汉族则呈现南北差异,即长江流域(江苏、安徽、湖北、浙江等)和东南沿海(湖南、福建和广东)存在差异。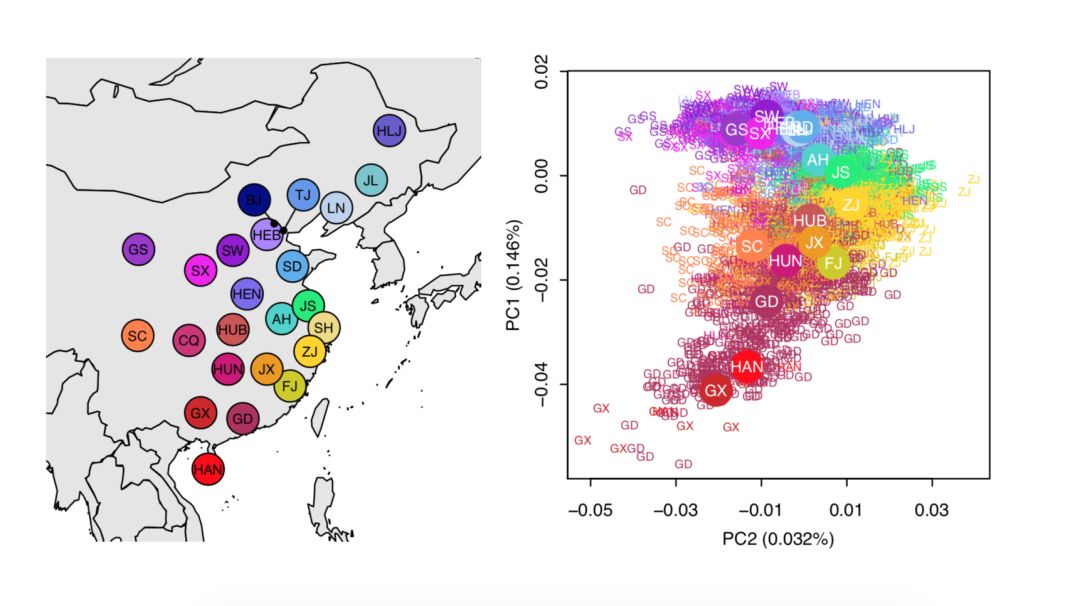
各色根据筛选标准选择了 3620 个代表用户,得到了跟上面这个研究类似的结果: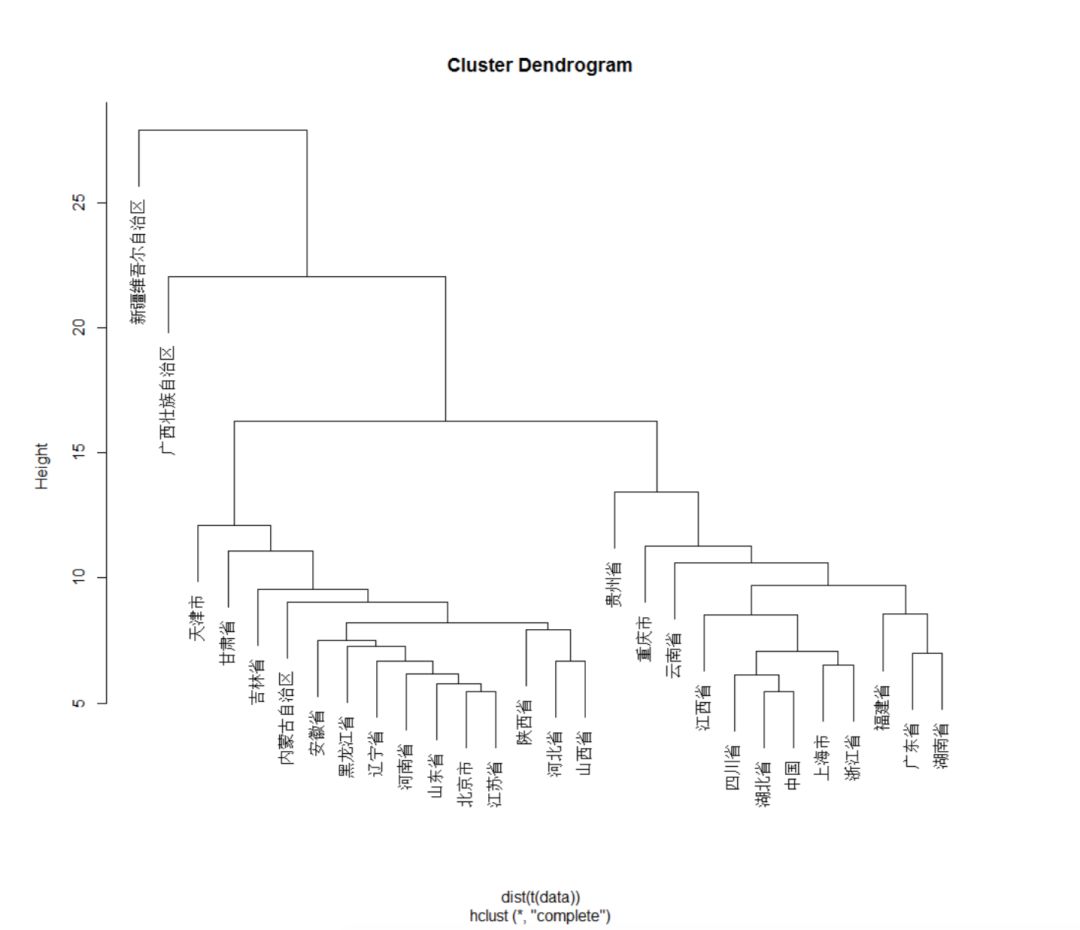
当地各色汉族用户较少的国内省市和自治区未包含,图中的分类「中国」为用户填写的原始数据
如果你觉得这张结构图看上去有点费解,你记住下面这几点就够了:
- 中国汉族可以分为南北两部分,南方汉族和北方汉族。
- 北方汉族中,甘肃与吉林省和其他省市存在差异,这可能是因为甘肃与新疆和内蒙相连,长期的民族融合交流会影响汉族的特异性;而吉林省满族人聚居,且东临朝鲜半岛。
- 天津市明显区别北方汉族的表现,让我们有些费解。希望有更多天津土著参与我们的检测,期待未来我们可以一起破解这一谜题。
- 南方的划分中,贵州省、重庆省和云南省与其他地区存在差异。其他地区可以分为长江以南和东南沿海两大部分。
根据层次聚类和 PCA 分析结果,我们选择了区域而非民族(南方汉族和北方汉族)来给大家进行祖源成分划分。
中国历史上多次人口迁徙和民族融合,比如四川省与湖北、江西和浙江等省市比较类似,我们都将其定义为「长江以南」地区。这也呼应了清朝初期「两广填四川」的人口迁移史。
 各色汉族划分
各色汉族划分
问题六:我是少数民族,为什么没有检测出来呢?
感谢许多少数民族用户给我的反馈,先不要着急。
因为少数民族用户比较少,且与汉族持续的融合交流,因此构建参考数据集难度更大。
我们用户中数量比较多的少数民族,如藏族、新疆地区少数民族,以及西南少数民族,都使用用各色用户数据作为参考数据库,其他少数民族,则参考了国外的公开数据库。
未来,随着数据库的持续构建,你会看到更多的祖源成分,了解你与更多地区与民族的联系。
 各色部分少数民族划分
各色部分少数民族划分
问题七:没有炫酷的祖源可以分享,那做祖源还有什么意义?
在各色所有检测项目中,祖源是大家最乐于分享和谈论的部分。
之前我也会想,为什么大家会关注自己的祖源成分,对现在的自己究竟有何意义?
听了很多用户的故事,我开始越来越理解,这些信息是一种联结,和过去所有人类进化历史的联结,和家庭父母的联结,而联结意味着对过去的关心、了解和想象。
尽管你时常感到孤独,但是我们并非凭空而来。如果我们做的所有数据积累与运算,能够引发你对人类和家族历史的好奇,能够让你重新开启你和自己父辈乃至祖父辈的亲密对话,那就是我们付出努力的最大价值。

我们仍在努力变得更好,这需要你的参与:
祖源的参考数据集随着数据积累也会不断优化,算法也是。这一版本的祖源成分产品还有一些局限性,比如:
1 我们的祖源参考数据集并未涵盖世界上所有的祖源成分。比如我们并未包含法国人的参考数据,所以会输出的结果是英国人和西班牙等法国临近地区的祖源成分结果。
各色用户中恰好有个法国人,他对自己的结果会有疑惑:
2 目前这个算法还有提升空间。
由于混血儿的染色体一半来自母亲,另一半来自父亲,针对典型混血儿的祖源成分推断,很重要的一步是区分自身基因数据的不同来源,这在生物学上叫 「phasing」。
做高质量的「phasing」需要更大数据积累,我们正在努力。希望下一版更新可以呈现给大家。
答疑环节到此结束。
最后我想说,从开启祖源升级项目,到今天能清楚地给大家讲述,我和各色的生信工程师们前后做了几个月的时间。
前期的收集和整理数据,解决多来源数据的兼容性,我们花了很多精力,当然更重要的是如何划分这些数据,确定最后呈现给大家的族群,这一步我们反复尝试了很多提取特征做分类的方法,尽管这一版本的分类还不够完美,我们希望尽量能给大家提供科学严谨的结果。
当然在这段时间内,也不断收到各色老用户的「问询」,非常感谢你们的陪伴。祖源产品,或者说所有的基因产品,是一个不确定的科学探索事业,很开心我们汇聚于此,怀着对生命的好奇不断探索,不断一起见证和推动自我和人类的认知边界。
最近各色完成了一次产品升级,接下来我们会继续提供更多新解读给大家,如使用神经网络算法预测的身高,某些慢性病风险的预测以及更丰富的心理特征解读等等,敬请期待。
根据各色后台的数据,我们发现,各色的用户都是一群乐于分享、富有爱心的人:每 5 个行动力用户中,会有 1 个会选择各色 DNA 检测包作为一份特别礼物,送给自己最在乎的朋友和家人。
我想,最好的礼物并不在于名贵奢侈,它应该是一个沟通的桥梁,让彼此能够通过了解而靠得更近;同时,它也为对方打开一个窗口,让对方看到自己变得更好的可能性。而各色的基因检测套装,就是这样一份有意义的礼物。
一份感谢自己、连接亲友的礼物,科学有爱又很酷,送给自己和你最想懂的人。